
Hvis reaksjonen din på den annonserte bortgangen til Google Reader var å skrike “Men mine stjernemerkede ting ! ”, Så er dette veiledningen for deg. Les videre når vi viser deg flere måter å trekke ut alle stjernemerkede artikler fra Google Reader.
Hvorfor vil jeg gjøre dette?
Google Reader legges ned 1. juli. Hvis du, som millioner av RSS-fans over hele verden, var Google Reader-fan, er det en god sjanse for at du brukte stjernefunksjonen til å flagge artikler for å holde fast i, for å lese senere eller for et annet formål.
Hvis du vil være trygg på at alle de stjernemerkede artiklene er trygge og sunne til tross for den forestående implosjonen av Google Reader, må du utføre noen få mindre trinn for å sikre at du har dataene i din besittelse og ikke lar deg rote på Googles servere.
Når du er ferdig med å følge opplæringen, har du (i det minste) en fil som inneholder alle stjernemerkede elementer og (avhengig av hvilket segment av opplæringen du bestemmer deg for å følge med) dine stjernemerkede elementer i en mer bruker- vennlig format.
Det er imidlertid en ting som ikke eksport eller automatiseringsmagi kan hjelpe med, og det er faktisk å behandle innholdet i de stjernemerkede artiklene. Hvis du har spilt artikler for å lese senere i mange år, vil du sannsynligvis bli sjokkert over hvor mange eksporterte artikler denne prosessen genererer. Du må kanskje bare sette av litt tid hver dag i noen uker for å grave gjennom den resulterende dumpen bit for bit.
Eksport av Google Reader-dataene dine med Google Takeout

Den aller første ordren er å bare få en kopi av alle Google Reader-dataene direkte i din besittelse. På denne måten, uansett hva som skjer med Reader-dataene dine på Googles servere i fremtiden, har du en kopi av den å jobbe med.
Google Takeout er et flott verktøy for å hente ut dataene dine fra alle slags Google-tjenester, men vi er bare interessert i Reader for denne veiledningen. Besøk Reader-delen av Google Takeout-verktøy her . Det vil ta et øyeblikk å beregne størrelsen på Takeout-filen. Når den er ferdig, klikker du på Opprett arkiv.
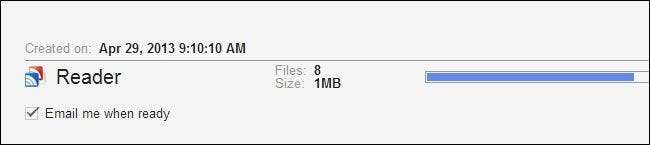
Til tross for at det ikke eksporterer hele Google-kontoen din, men bare en liten del av den, tar prosessen overraskende lang tid. Vi anbefaler at du sjekker "Send meg e-post når du er klar" og tar oss en kopp kaffe.
Når alt er gjort, klikker du på Last ned-knappen som vises nederst til høyre.
Gå videre og trekk ut arkivet til en arbeidskatalog, for eksempel Mine dokumenter, og legg selve arkivet på et trygt sted. Arkivfilene er ordnet slik:
[email protected].
.. [email protected]
... Leser
.... følgere.json
.... følger.json
.... likte.json
.... notater.json
.... delt av følgere.json
.... delt.json
.... starred.json
.... abonnement.xml
Det er to filtyper i arkivet: JSON og XML. JSON-filer (JavaScript Object Notation) er ganske enkelt en type datautvekslingsformat, og XML-filer (Extensible Markup Language) er en praktisk måte å merke et dokument på, slik at det er både maskinlesbart og menneskelig lesbart. Filen vi er mest interessert i for denne opplæringen er starred.json-filen, da den inneholder alle oppføringene for de stjernemerkede elementene dine.
Like viktig i den store ordningen med å frigjøre dataene dine fra Google Reader og flytte til grønnere beiter, er det imidlertid subscriptions.xml-filen. Denne filen inneholder alle RSS-abonnementene dine, og hvis du ønsker å importere alle de gamle abonnementene dine fra Google Reader til et nytt RSS-program, er dette filen du vil bruke til å gjøre det. Definitivt oppbevar den (og originalarkivet du lastet ned fra Google Takeout) på et trygt sted.
Konvertering av stjernemerkede elementer til bokmerker

En av de enkleste måtene å håndtere JSON-filen på er å bruke JSONview (en utvidelse tilgjengelig for begge Firefox og Chrome ). Denne metoden er best egnet for lesere med et lite antall stjernemerkede gjenstander i Google Reader (mindre enn 1000).
Installer utvidelsen for din respektive nettleser, og dra og slipp deretter starred.json-filen til en ny nettleserrute. Lagre den resulterende filen som et HTML-dokument. Deretter kan du svinge til høyre og importere HTML-dokumentet til din valgte nettleser, og det vil importere alle koblingene som nye bokmerker.
Det er imidlertid to ulemper ved denne teknikken. Den første er at du vil ende opp med noen dupliserte nettadresser i bokmerkefilen din, som domenenavn / hovedkilde-URL til artikler du ofte har stjernet (som for eksempel artikler fra How-To Geek) vil vises flere ganger. Det er litt irriterende, men ikke så stort.
Den andre ulempen er en avtalsbryter for folk med mange stjernemerkede ting (de av oss med tusenvis og tusenvis av stjernemerkede ting); når du har å gjøre med en veldig enorm HTML-import, går det bare ut og blir aldri ferdig. Dette er åpenbart en svært utilfredsstillende løsning for Reader-strømbrukere, siden den aldri fullfører import av de stjernemerkede artiklene dine. Hvis du er en strømbruker og har tusenvis av stjernemerkede gjenstander å håndtere, vil det bare ikke klippe det å importere dem som bokmerker.
Konvertering av stjernemerkede elementer til individuelle koblinger (og import til Evernote)
For den typen kraftig prosessorkraft brukere trenger (den typen behandling som kan kutte gjennom 5000+ stjernemerkede varer på få minutter), henvender vi oss til Python for å hjelpe oss å knuse oss gjennom den enorme listen vår.
Med tillatelse fra Paul Kerchen og Davide Della Casa, to Google Reader-strømbrukere som ønsket å eksportere alle de gamle stjernemerkene, har vi to veldig nyttige Python-skript som kan hjelpe oss med å gjøre en av to ting: 1) konvertere alle de stjernemerkede elementoppføringene til forskjellige HTML-dokumenter og / eller 2) importerer alle våre stjernemerkede varer til Evernote.
For begge triksene må du ha Python installert på systemet ditt. Ta en kopi av Python for operativsystemet og installer det før du fortsetter.
Etter å ha installert Python, besøk nettstedet for Kerchen / Casas Google Reader Export-prosjekt og lagre eksport2HTMLFiles.py- og export2enex.py-filene i samme mappe som du ekstraherte starred.json-filen til.
Hvis du ønsker å konvertere alle de stjernemerkede elementene dine til forskjellige HTML-filer, kan du gjøre det ved hjelp av export2HTMLFiles.py ved å utføre følgende kommando i katalogen der starred.json-filen er lagret:
python export2HTMLFiles.py
(Hvis python ikke er utpekt som en systemomfattende kommando på maskinen din, må du erstatte "python" med hele banen til den python-kjørbare filen, f.eks. C: \ Python2.7 \ python.exe)
Avhengig av antall stjernemerkede varer du har, kan denne prosessen ta alt fra noen få sekunder til flere minutter. Det tok rundt tre minutter å rive gjennom 12 000 stjernemerkede gjenstander under testen.
Når det er gjort, har du en serie med nummererte og navngitte HTML-filer (f.eks. 1 artikkel du stjernemerket.html til 10000 eller annen artikkel du stjernemerket.html). Den enkleste måten å se på dem alle er å bare laste den lokale katalogen i nettleseren din.
Dette er en fin måte å frigjøre stjernemerkede elementer fra Google Reader og JSON-filen, men som du nevnte tidligere i opplæringen, hvis du har lagret artikler for å lese dem senere i mange år nå, vil du ha en monumental oppgave på dine hender.
En måte du bedre kan håndtere denne oppgaven på, er å bruke Evernote som arbeidsområde for å sortere, merke og potensielt slette ikke lenger nyttige stjernemerkede elementer.
Det er to måter du kan gjøre om å importere varene til Evernote. Du kan importere HTML-filene vi opprettet for et øyeblikk siden ved å bruke Importer mappe. I Evernote-skrivebordsklienten din kan du gå til Verktøy -> Importer mapper og deretter opprette en dumpmappe for HTML-filene. Vi laget en undermappe i / Reader / arbeidsmappen kalt Imports og en ny notisbok i Evernote som heter Starred Items. Ved å dra og slippe HTML-filene i / Reader / Imports / mappen, kan vi importere dem som forskjellige notater i Evernote-mappen Stjernemerkede elementer. De lagres permanent der for å bli vurdert på fritiden.
Alternativt, hvis du ønsker å konvertere alle de stjernemerkede elementene dine til en innfødt Evernote-notatbok i ett øyeblikk, kan du bruke det andre Python-skriptet du lastet ned, export2enex.py for å gjøre det. Fordelen med å gjøre det er at det gjør en litt bedre jobb med å bevare formateringen av dokumentene.
Utfør følgende kommando i mappen der starred.json-filen ligger:
python export2enex.py> StarredImport.enex
Ta den resulterende filen StarredImport.enex og importer den til din Evernote desktop-klient ved hjelp av File -> Import -> Evernote Export Files.
På dette tidspunktet har du frigjort de stjernemerkede artiklene dine, i sin helhet, fra Google Reader, og du er klar til å gå ned til den (potensielt lange) virksomheten med å sortere gjennom haugen.
Har du en smart måte å manipulere JSON-filen og trekke ut de stjernemerkede elementene? Bli med i diskusjonen nedenfor og del dine tips og triks med dine andre lesere.






